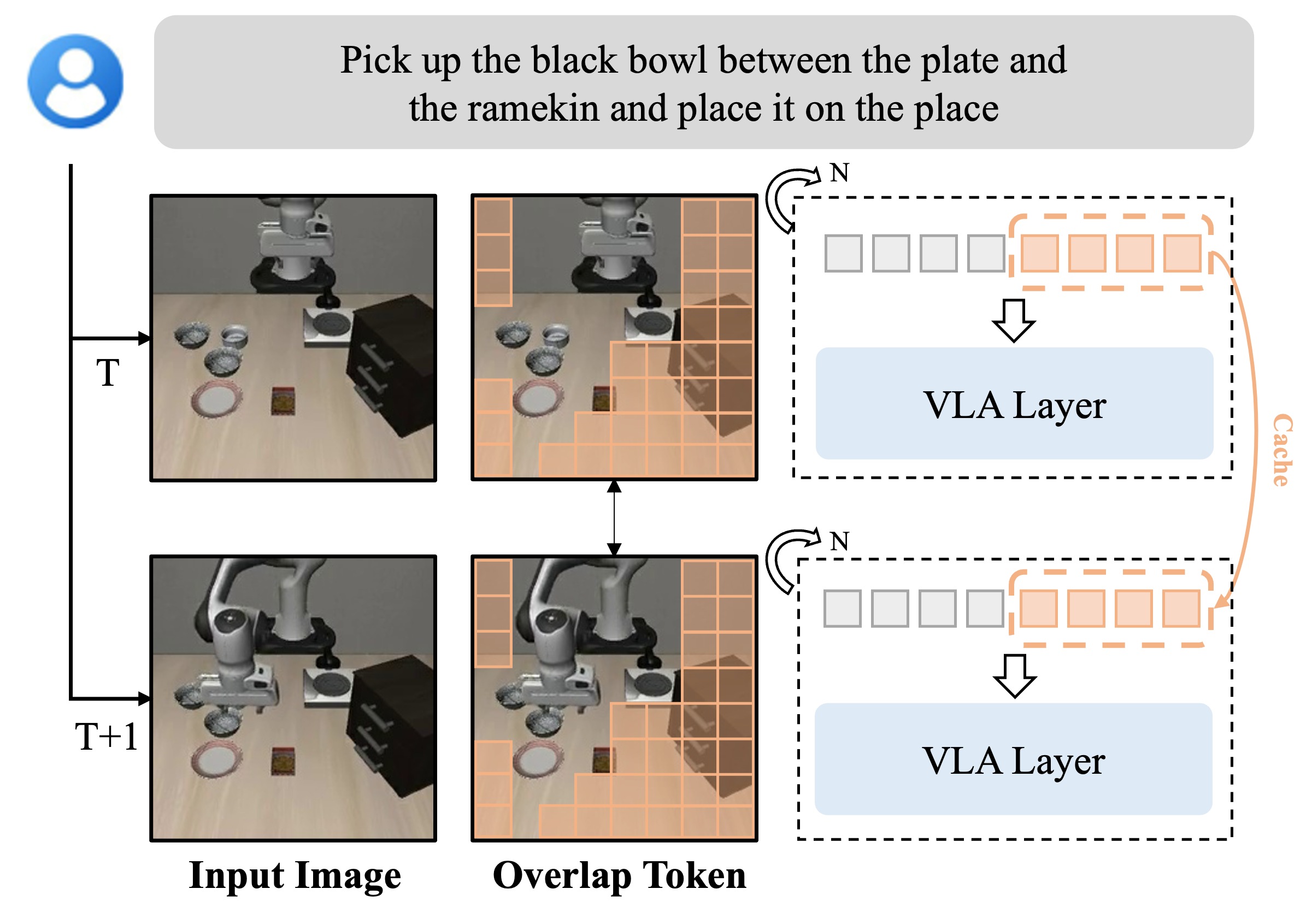
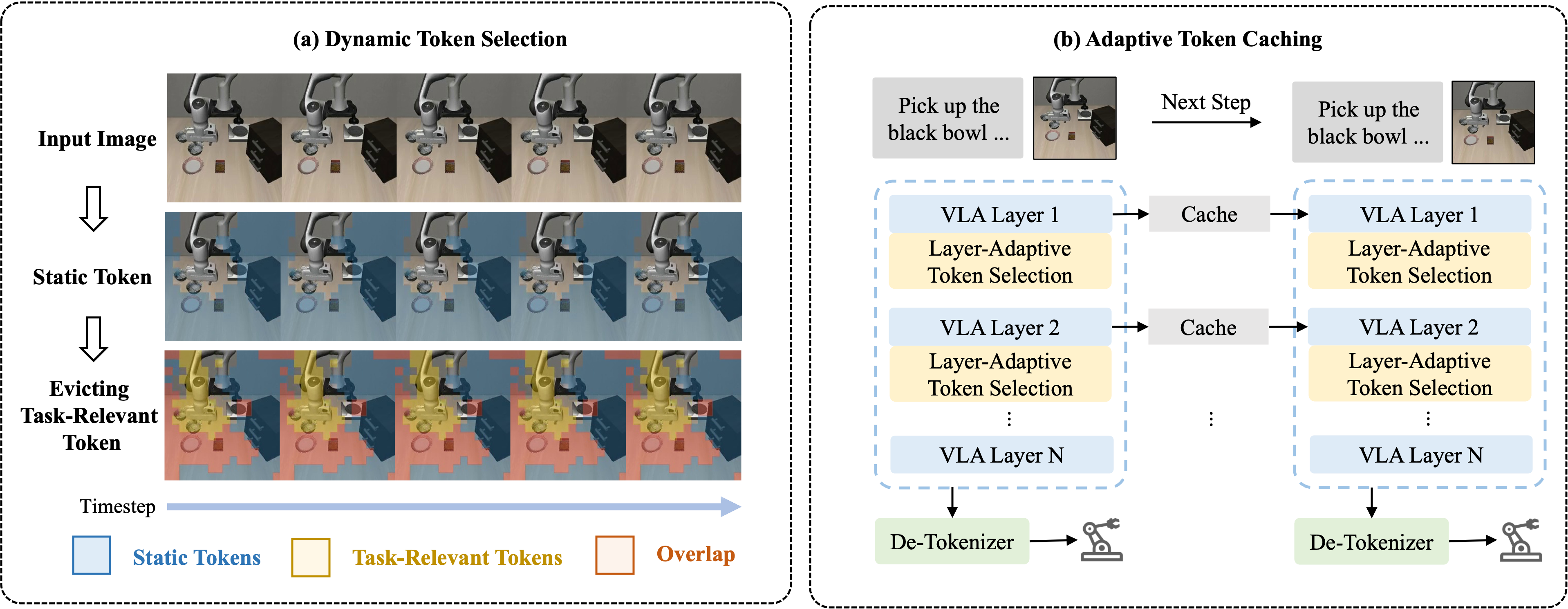
Vision-Language-Action (VLA) models have demonstrated strong multi-modal reasoning capabilities, enabling direct action generation from visual perception and language instructions in an end-to-end manner. However, their substantial computational cost poses a challenge for real-time robotic control, where rapid decision-making is essential. This paper introduces VLA-Cache, a training-free inference acceleration method that reduces computational overhead by adaptively caching and reusing static visual tokens across frames. Exploiting the temporal continuity in robotic manipulation, VLA-Cache identifies minimally changed tokens between adjacent frames and reuses their cached key-value representations, thereby circumventing redundant computations. Additionally, to maintain action precision, VLA-Cache selectively re-computes task-relevant tokens that are environmentally sensitive, ensuring the fidelity of critical visual information. To further optimize efficiency, we introduce a layer adaptive token reusing strategy that dynamically adjusts the reuse ratio based on attention concentration across decoder layers, prioritizing critical tokens for recomputation. Extensive experiments on two simulation platforms (LIBERO and SIMPLER) and a real-world robotic system demonstrate that VLA-Cache achieves up to 1.7x speedup in CUDA latency and a 15% increase in control frequency, with negligible loss on task success rate.
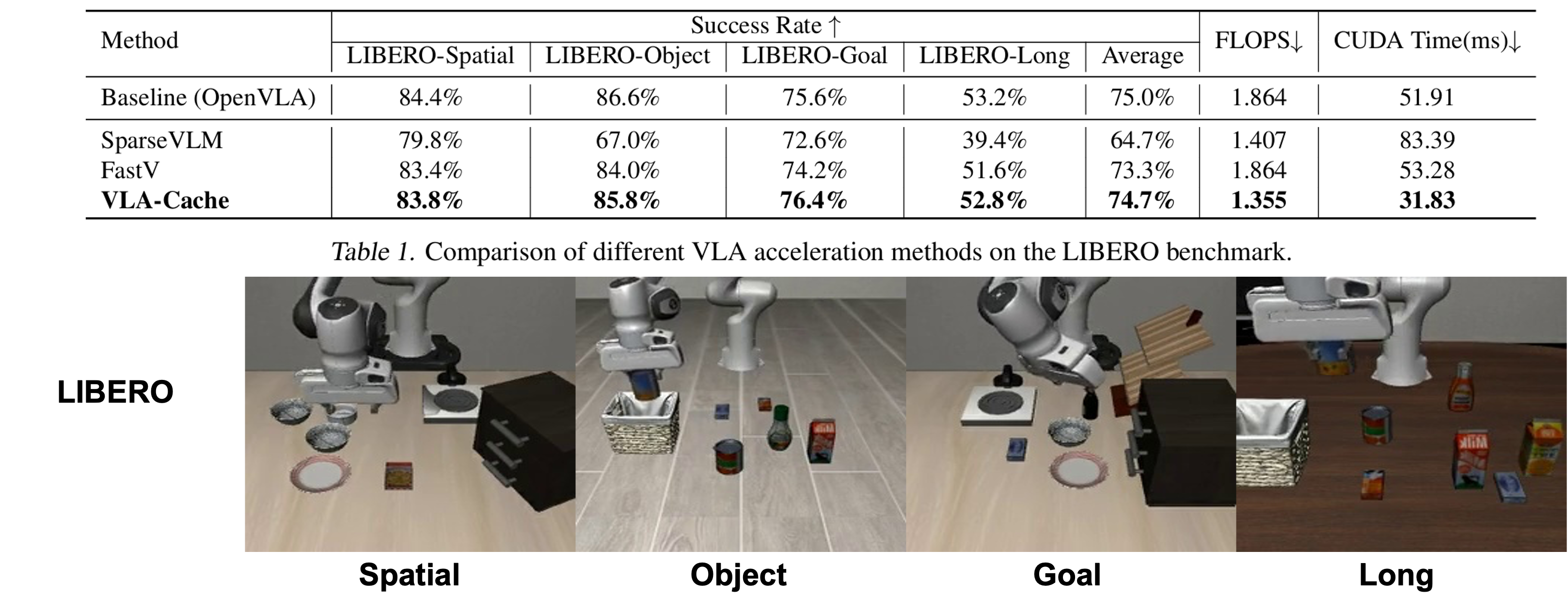
Comparison of VLA-Cache with other VLM caching acceleration algorithms on the LIBERO environment, using OpenVLA as the baseline model. We report the success rate, as well as the FLOPS and CUDA Time during the language backbone decoding process.
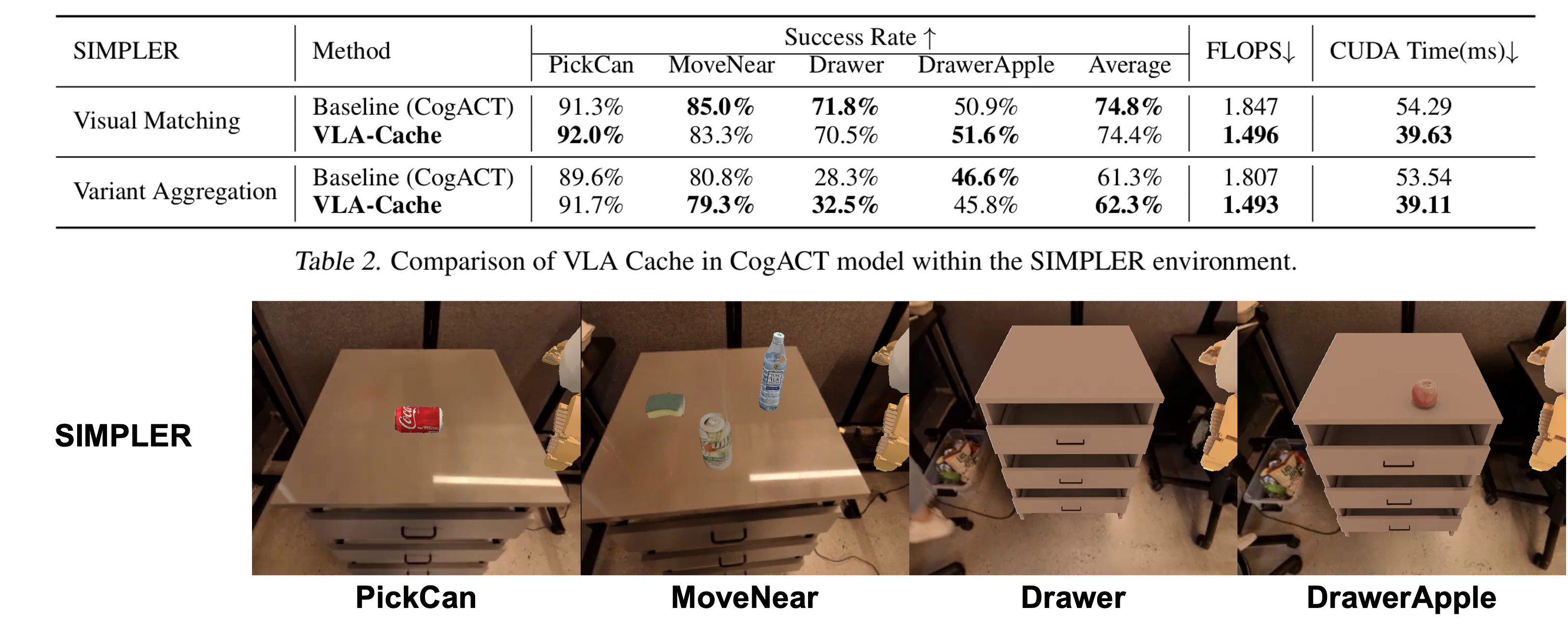
Comparison of VLA-Cache with the baseline model CogACT on the SIMPLER environment. We report the success rate and inference efficiency. The results are presented for the Google robot arm in two SIMPLER settings: Visual Matching and Variant Aggregations.
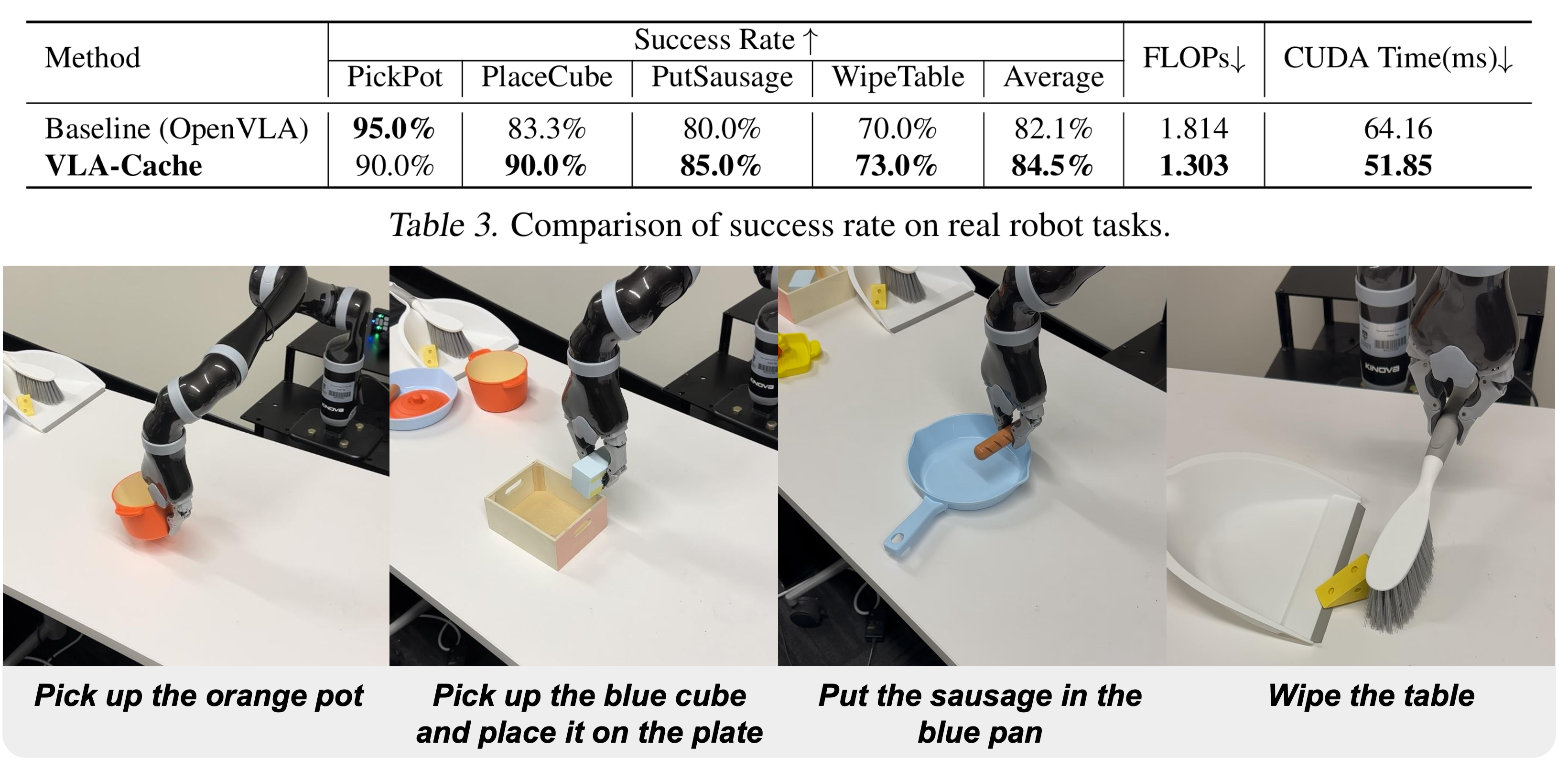
Comparison of VLA-Cache with the baseline model OpenVLA on the real-world environment. We report the success rate and inference efficiency across four different tasks. In the real-world tasks, a Kinova Jaco2 robot arm was used to collect demonstrations and fine-tune OpenVLA as the baseline model. We also report the average performance across all tasks.
@article{xu2025vla,
title={VLA-Cache: Efficient Vision-Language-Action Manipulation via Adaptive Token Caching},
author={Xu, Siyu and Wang, Yunke and Xia, Chenghao and Zhu, Dihao and Huang, Tao and Xu, Chang},
journal={arXiv preprint arXiv:2502.02175},
year={2025}
}|
|